

 Login
Login

 November 20, 2023
November 20, 2023|
Voiced by Amazon Polly |
Overview
In today’s data-driven world, securely and efficiently moving data to the cloud is essential for businesses of all sizes. Amazon Web Services (AWS) provides a range of services to facilitate this process, and one such service is AWS DataSync. AWS DataSync simplifies data transfer between on-premises systems and AWS services. This blog will guide you through migrating data from an on-premises Linux server to Amazon S3 using AWS DataSync.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Introduction
In the fabric of modern business, data is the lifeblood that fuels innovation, decision-making, and competitiveness. The importance of data migration cannot be overstated, representing a pivotal step in harnessing the full potential of cloud computing.
Amazon S3 –
At the heart of this migration lies Amazon Simple Storage Service (S3), a cornerstone in AWS’s suite of storage services. Amazon S3 provides virtually limitless, highly durable, and scalable object storage. Its simple features, like versioning, lifecycle management, and robust security options, make it an ideal destination for storing diverse datasets. Migrating data to Amazon S3 not only ensures accessibility but also sets the stage for leveraging other AWS services, such as analytics, machine learning, and archival solutions.
Amazon EC2 Instances –
While Amazon S3 serves as the repository, Amazon Elastic Compute Cloud (EC2) instances play a crucial role in migration. Amazon EC2 instances provide scalable computing capacity, allowing you to launch virtual servers tailored to your needs. In the context of data migration, Amazon EC2 instances host the AWS DataSync agent, facilitating the smooth and secure data transfer between your on-premises Linux server and Amazon S3.
Small Services – Orchestrating Efficiencies
In addition to the foundational services, smaller yet equally vital AWS services come into play. Amazon CloudWatch Events, for instance, can be employed to automate triggers for AWS DataSync tasks based on specific events or schedules. AWS Step Functions provides a serverless orchestration service to coordinate multiple AWS services into serverless workflows, enhancing automation and efficiency in the data migration process.
As we delve into the step-by-step guide for migrating data using AWS DataSync, Amazon S3, and Amazon EC2, these auxiliary services will work in tandem, providing a holistic and optimized solution for the intricacies of data migration in the cloud.
Prerequisites
Before you start the migration process, ensure you have the following in place:
- AWS Account: You need an AWS account to use AWS DataSync.
- On-Premises Linux Server: The server you want to migrate data from should be running.
- AWS DataSync Agent: Install the AWS DataSync agent on your Linux server. You can download it from the AWS Management Console.
Step-by-Step Guide
Step 1 – Create an Amazon S3 bucket where you want to migrate your data.

Step 2 – Connect to your Linux server and find the AMI to create an agent.
|
1 |
aws ssm get-parameter --name /aws/service/datasync/ami --region your_region |

Step 3 – Copy this and replace your ami and paste it into the browser.
|
1 |
https://console.aws.amazon.com/ec2/v2/home?region=yourregion#LaunchInstanceWizard:ami=yourami |
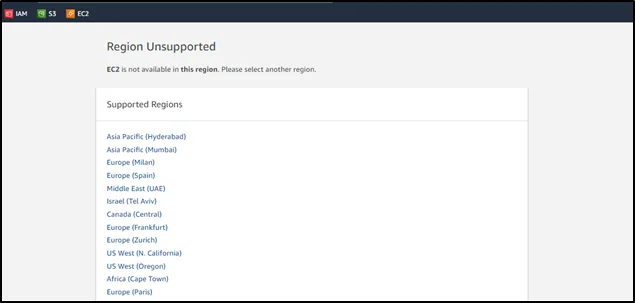
Step 4 – Now select the region and create an agent instance.

Step 5 – Now go to AWS DataSync and create an agent.

Step 6 – Now, paste the public IP of the agent Instance created above:

Step 7 – Click on Get Key.

Step 8 – Give the name of the agent and click Create Agent.

Step 9 – Agent Created Successfully.

Step 10 – Add your Agent IP to the Linux server from which data is ready to migrate.
|
1 2 |
sudo vi /etc/exports /home/tecmint/my_nfsshare agentIP(rw,sync,no_root_squash,no_subtree_check) |

Step 11 – Choose “Source location” and select your on-premises Linux server. Specify the path to the data you want to migrate and the Public IP.

Step 12 – Choose “Destination location” and select your Amazon S3 bucket. Specify the Amazon S3 bucket name and path.

Step 13 – Configure the task settings, such as scheduling, logging, and bandwidth settings, according to your requirements.
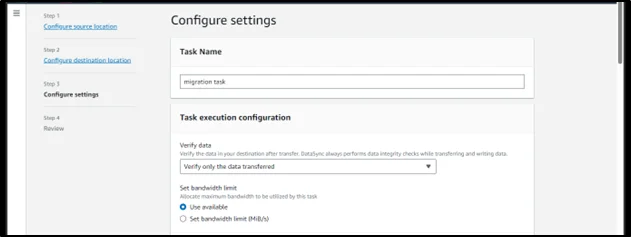
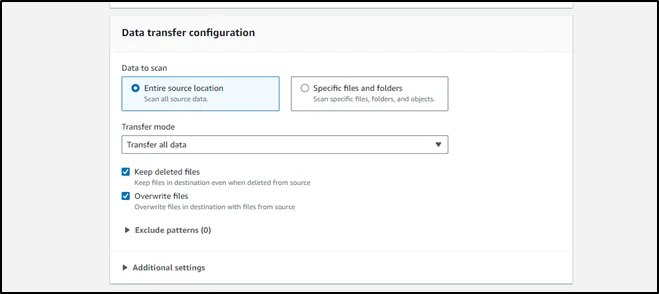


Step 14 – Review and create the task.

Step 15 – Click the “Actions” dropdown and choose “Start”.
Step 16 – Monitor the task’s progress in the AWS DataSync Console.

Step 17 – Check your Amazon S3 bucket to ensure that the data has been successfully migrated.

Conclusion
Migrating your data from on-premises Linux servers to Amazon S3 using AWS DataSync is a strategic move that can streamline your data management processes, enhance accessibility, and bolster the security of your valuable information. This step-by-step guide has provided you with a roadmap to accomplish this migration, but let’s reflect on the broader implications of this process.
Drop a query if you have any questions regarding Amazon S3 and AWS DataSync and we will get back to you quickly.
Want to save money on IT costs?
- Migrate to cloud without hassles
- Save up to 60%
About CloudThat
CloudThat is an official AWS (Amazon Web Services) Advanced Consulting Partner and Training partner, AWS Migration Partner, AWS Data and Analytics Partner, AWS DevOps Competency Partner, Amazon QuickSight Service Delivery Partner, Amazon EKS Service Delivery Partner, and Microsoft Gold Partner, helping people develop knowledge of the cloud and help their businesses aim for higher goals using best-in-industry cloud computing practices and expertise. We are on a mission to build a robust cloud computing ecosystem by disseminating knowledge on technological intricacies within the cloud space. Our blogs, webinars, case studies, and white papers enable all the stakeholders in the cloud computing sphere.
To get started, go through our Consultancy page and Managed Services Package, CloudThat’s offerings.
FAQs
1. How do I monitor the progress of my data migration with AWS DataSync?
ANS: – You can monitor the progress of your migration using the AWS Management Console or the AWS Command Line Interface (CLI). AWS DataSync provides detailed metrics and logs to track the status and progress of your data transfer.
2. What are the key data transfer speed and performance considerations with AWS DataSync?
ANS: – AWS DataSync is designed for high-speed data transfer. Consider factors like network bandwidth, instance types, and parallelism settings to optimize speed and performance when configuring your AWS DataSync task. Additionally, you can use AWS Data Sync’s automated data validation feature to ensure data integrity.
3. Can I automate data migration tasks with AWS DataSync?
ANS: – Yes, you can automate data migration tasks by using Amazon CloudWatch Events, AWS Step Functions, or other AWS services to trigger AWS DataSync tasks based on specific events or schedules.

WRITTEN BY Noopur Shrivastava
Noopur Shrivastava works as a Research Associate at CloudThat. She is focused on gaining knowledge of the Cloud environment. Noopur loves learning about new technology and trying out different approaches to problem-solving.









Comments